Forest and Greenhouse Effect – Sink or Source?
Forests play an important role in maintaining the global carbon as they are the primary source of biomass which in turn contains a vast reserve of carbon dioxide, an important greenhouse gas. Of all terrestrial ecosystems, forests contain the largest store of carbon and have a large biomass per unit area. The main carbon pools in forests are plant biomass (above- and below-ground), coarse woody debris, litter and soil containing organic and inorganic carbon (Nizami et al, 2009). The ability of forests to both sequester and emit greenhouse gases coupled with ongoing widespread deforestation has resulted in forests and land-use change.
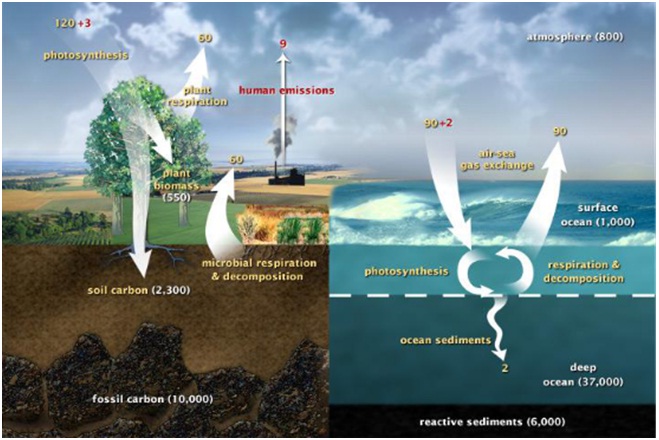
Since we were kids, we were all told in biology class that vegetation can absorb carbon dioxide from atmosphere, stored as organics and release oxygen through photosynthesis. In fact, there are other processes that we are not familiar with. The carbon which forest stored through photosynthesis is almost the same amount as those released by plant respiration, microbial respiration & decomposition in mature forests. Thus, forests may only work as carbon sink when they are in their growing stage (There is another theory that some mature forests start to work as sink again these years due to the carbon fertilization caused by greenhouse effect ). On the contrary, forest disturbance may release carbon from forest carbon pool to atmosphere, therefore aggregate greenhouse effect. So accurate estimation of forest biomass, hence carbon storage is of crucial importance to monitor carbon change dynamics. This knowledge will help us know how much carbon was released and how much can be restore in the future for better management.
What is Tree Biomass ?
Our fundamental knowledge of Forest AGB is based on destructive sampling in field, by choosing trees samples from different species, cutting them down, measuring tree metrics (normally tree height), diameter at breast height (DBH), weighing their dry weight in lab, then developing regression models between biomass and these metrics based on tree species. Finally these biomass models, normally as a function of DBH and tree height will be used to estimate biomass in larger area.
How Do We Monitor Biomass In a Large Scale in the Past?
Forest Inventory-Time & Money Consuming
Traditionally, extensive forest biomass estimation mainly rely on national forest inventory, gathering tree metrics (DBH, tree height etc.) for selected representative sites, which usually take years of time and large amount of manpower and money, not even to mention multi-temporal observation for change detection. And always, using small area to represent the whole picture can lead into bias.
Optical Remote Sensing – an Economical Way
The most mature and widely used technique is space-borne optical remotely sensing(Landsat, MODIS etc.). They can provide global seamless coverage repeatedly in a very short period.
However, signals optical images observe mostly reflected from surface of forests. These sensors can not provide vertical structure information which are more directly related to biomass and carbon storage. Also, they are very limited to weather conditions, which hindered its potential for accurate biomass estimation.
Microwave Remote Sensing – Better choice
Comparing with space-borne optical sensors, space-borne synthetic aperture radar (SAR) has stronger penetrating power, especially L-band and P-band signal with long wavelength can penetrate tree crown, bouncing from branches and tree trunks to receiver. These back scatters are related to vertical structure of forests, which can be used for canopy height hence biomass modeling (Ranson and Sun, 1994). However, the uncertainty of microwave remote sensing increases with the complexity of topography. Also, in dense forests, SAR back scatters can saturate easily. These limitations hindered its usage in large scale biomass mapping.
Airborne LIDAR – Accurate But Expensive
Light detection and ranging (LiDAR) can provide detailed information about 3D tree structure. It is by far the most accurate way to measure tree structural metrics, such as crown cover, tree height, canopy height and tree density. Has been widely used in regional forest above-ground biomass study and has been proved that biomass it estimated is closely related to field measurements. However the massive data volume and time and money consuming impede its usage in large area observation. The common method is to use airborne lidar systems as sampling method to extrapolate structural information and biomass against space-borne optical data set or space-borne SAR image which have complete coverage, which can also solve the scale mismatch problem between field measurement and space-borne data.

What Can Be Done in the Future?
Developing Accurate Species Specific Allometric Equations
Currently, forest biomass estimation in large scales mainly rely on general allometric equations developed from average conditions of many tree species as species specific allometric equations for many species simply do not exist, which would lead large uncertainty into the final results at the first place. In order to improve estimating accuracy in the future, species base allometric equations or more accurate general models should be developed.
Future Sensors
The new launched Sentinel-2 with its freely available multi-spectral data will be used in supporting forest monitoring, land cover change detection and natural disaster management. The first satellite, Sentinel-2A was lunched on 23 June 2015, and Sentinel-2B is planned to be lunched in mid of 2016. The Multi-Spectral Instrument (MSI) has 13 spectral bands from the visible to short-wave infrared(SWIR) with four at 10m, six at 20m and three at 60m resolution, with narrower bands and additional red channels compared to Landsat OLI for identification and assessing vegetation, and dedicated bands for improving atmospheric correction and detecting clouds(Drusch et al., 2012).
BIOMASS satellite with P-band (435Mhz, ~69m wavelength) will be launched by European Space Agency (ESA) in 2020 to generate 200 m resolution forest AGB map at global scale. Combining Airborne lidar measurements, initial tomographic phase using polarimetric SAR (PolSAR) images will be used to estimate forest AGB for low biomass areas, while in dense forests, PolInSAR phase will be used to extract tree height information and then convert to AGB using allometric equation derived from field measurements (Minh et al., 2016).
SAOCOM satellites (1A and 1B), both will be equipped with a L-band (about 1275 GHz) full polarimetric Synthetic Aperture Radar (SAR), the launch dates currently are scheduled on October 2017 and October 2018. And also a L-band (24-centimeter wavelength) polarimetric SAR will be settled on NASA-ISRO SAR Mission (NISAR) schedule at 2019-2020.
A conceptual study of space-borne vegetation LiDAR called MOLI (Multi- Footprint Observation LiDAR and Imager) was conducted by Japan Aerospace Exploration Agency. If this plan finally settled, combining with airborne lidar, this will enable the appearance of the most accurate global biomass map.
Combination of Active and Passive Remote Sensing Observation
Combining different information extracted from multiple sensors will be the main trend for future above ground biomass estimation, such as combining space-borne optical multi-spectral data set and airborne hyperspectral, space-borne SAR and airborne lidar.
Modeling Biomass Using Non-parameter Machine Learning Models
The developing trend of modeling methods is a transfer from parameter methods like Multiple linear regression to complex machine learning models such as Decision tree, Artificial Neural Network (ANN), Support Vector Regression (SVR) etc.
References
DRUSCH, M., DEL BELLO, U., CARLIER, S., COLIN, O., FERNANDEZ, V., GASCON, F., HOERSCH, B., ISOLA, C., LABERINTI, P. & MARTIMORT, P. 2012. Sentinel-2: ESA’s optical high-resolution mission for GMES operational services. Remote Sensing of Environment, 120;25-36.
MINH, D. H. T., LE TOAN, T., ROCCA, F., TEBALDINI, S., VILLARD, L., RÉJOU-MÉCHAIN, M., PHILLIPS, O. L., FELDPAUSCH, T. R., DUBOIS-FERNANDEZ, P. & SCIPAL, K. 2016. SAR tomography for the retrieval of forest biomass and height: Cross-validation at two tropical forest sites in French Guiana. Remote Sensing of Environment, 175;138-147.
NIZAMI, S. MIRZA, & S. LIVESLEY. 2009. “Estimating carbon stocks in sub-tropical pine (Pinusrox burghii) forests of Pakistan,” Pak J AgriSci. Vol. 46(4)
RANSON, K. J. & SUN, G. 1994. Mapping biomass of a northern forest using multifrequency SAR data. Geoscience and Remote Sensing, IEEE Transactions on, 32; 388-396.